DAX
-
Optimizing Rolling Distinct Count Measures

Introduction In my new role in Azure Data, I have spent a lot of time optimizing the performance of semantic models and DAX measures. One of the types of calculations we frequently use is 28-day (or 7-day) rolling distinct counts in order to see how our business is growing over time. In this post, I Continue reading
-
Creating User-Driven Default Slicer Selections

Introduction Recently, in an internal Power BI help forum, someone asked if there was a way to force a slicer’s default selection to be based on a particular user’s sign in. I thought it was an interesting challenge and wanted to share my proposed solution here. The Requirements The requirements were: To simplify the demo, Continue reading
-
Sometimes It’s Good to Fail: Raising Errors with Data Quality Tests

Introduction Having your dataflows or semantic models fail to refresh can be frustrating, but at least you know that whatever caused the error did not make it into your production assets. Your data might be stale, but you have the ability to go into the code, make the fix, and kick off another refresh. Something Continue reading
-
Reducing Semantic Model Size with Creative Solutions
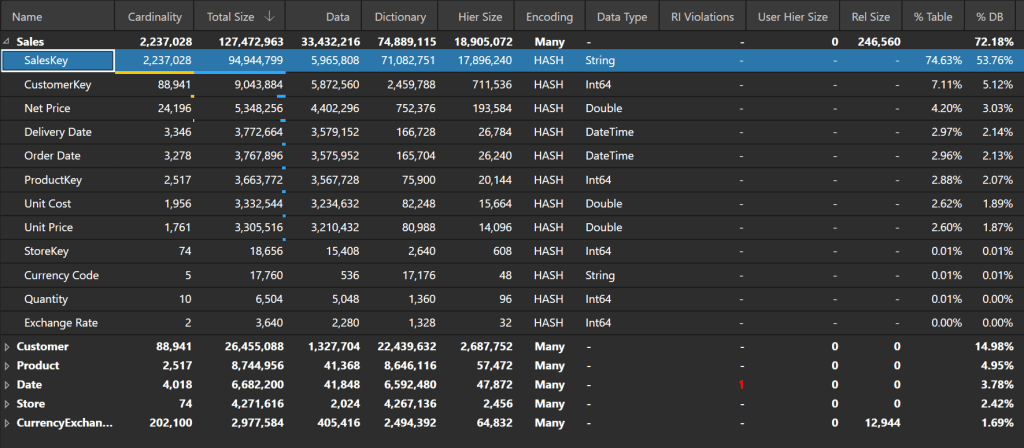
Introduction When working with larger semantic models, one of the things you are constantly trying to do is to reduce the model size while still meeting stakeholder requirements. Smaller models often result in faster queries, and you need to keep models under a certain size to stay within capacity memory limits. One common problem child Continue reading
-
Enhancing Your Golden Semantic Model with User Input Tables

Introduction While learning about Power BI, you are likely to learn that designing a star schema consisting of fact and dimension tables is critical to building a good semantic model. You will also learn that it is best practice to create “Golden” models that can be used to support multiple reports instead of creating a Continue reading
-
Custom M Function #7: fxReplaceWithDefaultValue

Introduction Click here to go straight to the function. When cleaning data, one thing you have to consider is how to handle null or blank values. My preference is to replace them with an alternative default value such as the string “Unknown.” Blanks and nulls can cause confusion for users. Consider the image below: As Continue reading
-
Custom M Function #6: fxSplitCamelCaseColumns
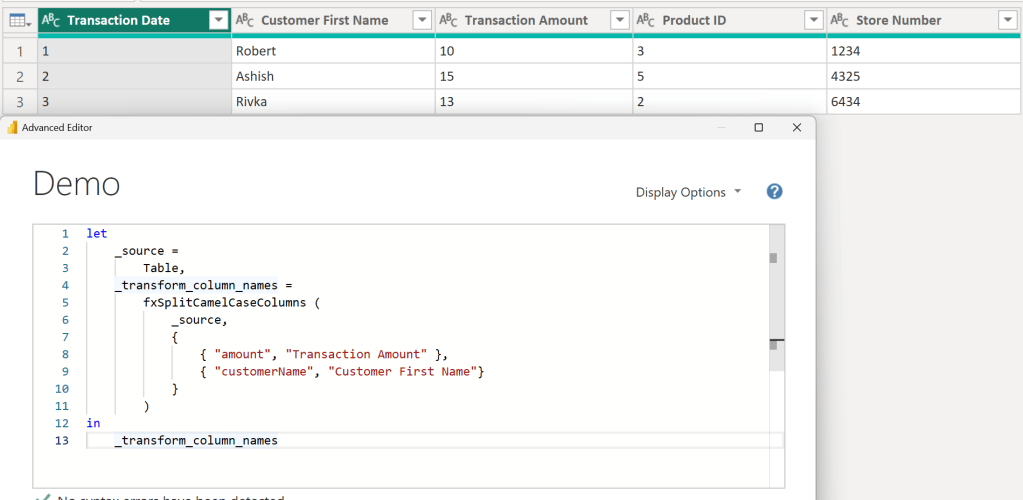
Introduction Click here to go straight to the function. In a previous post, I shared a custom function called fxSplitCamelCaseText that splits a string stored in camel or pascal case into multiple words separated by spaces. That function was created primarily to be used in another function called fxSplitCamelCaseColumns that converts all camel/pascal case columns Continue reading
-
You Don’t Know Until You Test It: DAX Optimization

Introduction When working with DAX, there are many ways to get the same result, but performance can vary greatly. If you are anything like me, you want your code to be as performant as possible. Sometimes you have a good idea about what pattern is best and other times you don’t. There are even times Continue reading
-
Custom M Function #5: fxCumulativeToIncremental

Introduction Click here to go straight to the function. *Big thanks to Gil Raviv for his cumulative to incremental article for helping me get started creating this custom function.* When working with data in Power BI, my preference is to work with fully additive facts. Kimball briefly explains fact additivity here: The numeric measures in Continue reading
-
Power Query Level Up: Exploring the Advanced Editor and the M Language

Recently, I had the privilege of delivering my first public training session at the 2024 Global Power Platform Bootcamp where I gave an introduction to the Power Query Advanced Editor and the M Language. I’ve included a recording of the training below. Making the leap from the Power Query UI to using the Advanced Editor Continue reading
